ローカルで Ollama 動かして VS Code の GitHub Copilot でつかう
この記事も含め、技術系の話題は今後 www.mochive.dev で更新します。
タイトルを読んで字の如し、Ollama というLLMを動かせるツールをつかってローカルでLLMを動かして、VS Code の GitHub Copilot 拡張機能のチャットやコード補完をやってもらおうというハナシ。
2025年5月から GitHub Copilot が有料版でもある程度の上限が設けられるみたいなので、いざというときの逃げ道のため (という口実で技術的興味を満たすため) にやってみる。
LLMのこととか全然詳しくないので素人のお遊び程度にどうぞ。
環境
- OS: Windows 11 Home
- CPU: Ryzen 7 3800X
- RAM: 56GB
- GPU: RTX 3060 12GB
Ollama のインストール
Ollama公式サイトからインストーラーを落としてインストールするだけ。
Ollama はGUIソフトではない (たぶん) なので、インストール後に何もウィンドウが出てなくても心配しなくていい。
タスクトレイにラマのアイコンが表示されていればOK。
モデルのインストール
今回は最近よく名前を聞く Qwen3 を試してみる。Ollama のライブラリに登録されているのでモデルファイルの用意とかは必要なく、コマンドひとつで走らせることができる。
コマンドプロンプトを開いて以下のコマンドを打つ。
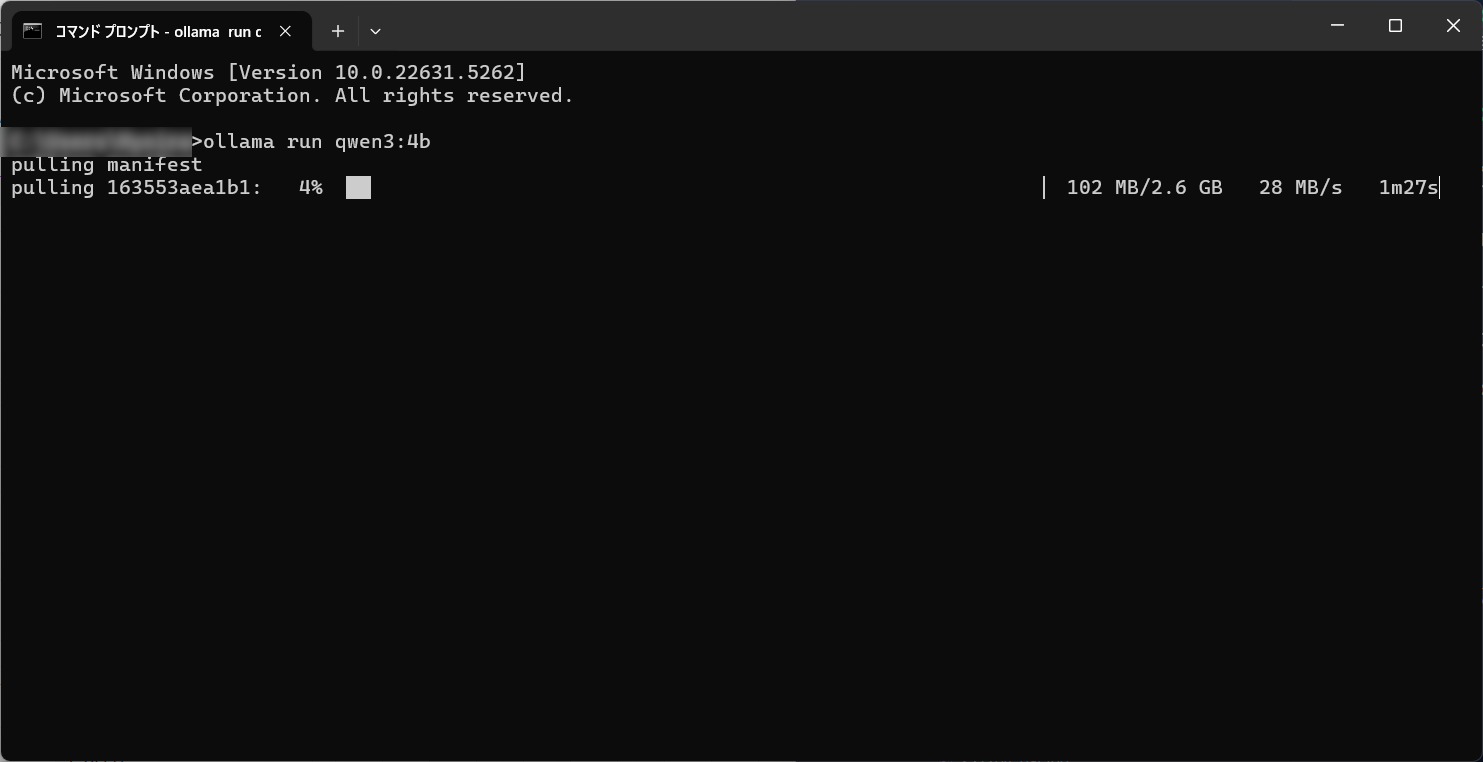
ollama run qwen3:4b
モデルサイズがいろいろあるけど、とりあえず軽量でそこそこ動くらしい4Bモデルでやってみる。
初回は数GBのダウンロードが入るのでしばし待つ。
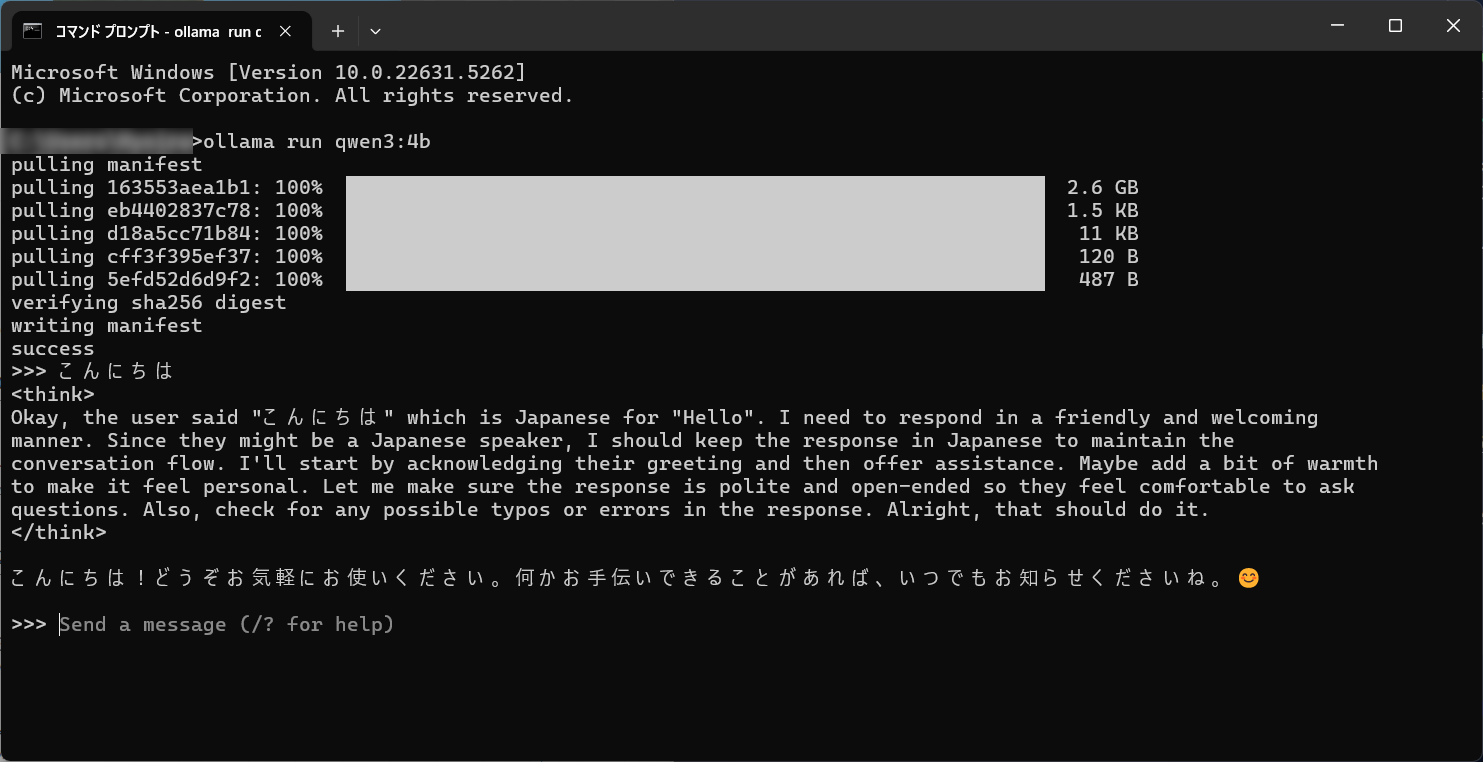
ダウンロードが完了するとチャットモードが起動する。ここでおしゃべりもできるが、今回はつかわないので Ctrl+D でチャットモードを抜ける。
ちなみに ollama ps と打つと現在動いているモデルやつかっているプロセッサの種類が確認できる。
1
2
3
>ollama ps
NAME ID SIZE PROCESSOR UNTIL
qwen3:4b a383baf4993b 5.2 GB 100% GPU 3 minutes from now
VS Code で設定する
公式ドキュメントに「Bring your own language model key」として載っているので簡単に説明。
VS Code で GitHub Copilot 拡張機能を入れて、チャット画面下部のモデル選択ボタンから “Manage Models” をクリックする。
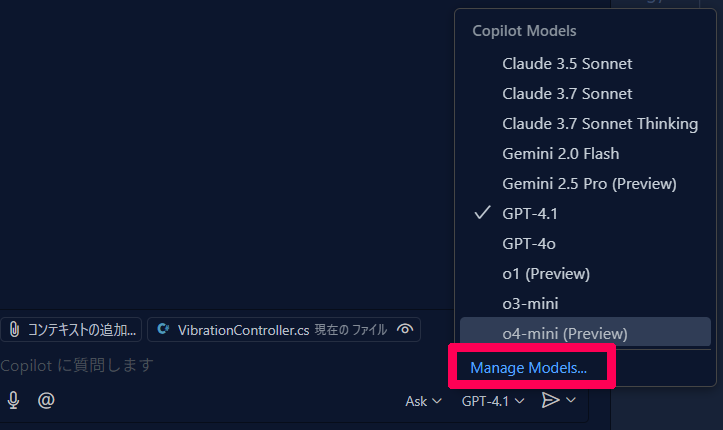
出てきた provider の中から Ollama を選ぶ。
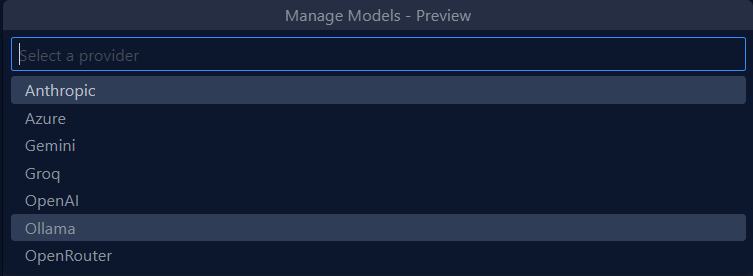
現在動いているモデルが表示されるので、Qwen3:4B にチェックを入れてOKを押す。(ここでは14Bも動かしているケド)

すると先程のモデル選択の中に Qwen3 が出てくるので、他のモデルと同様に選んでつかうことができるようになる。
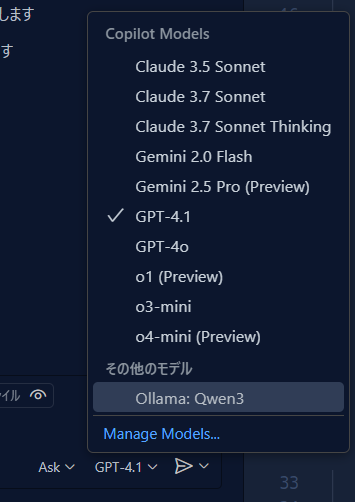
つかってみた感想
ライトな使い方ならけっこう使えそうな雰囲気を感じる。
14Bモデルにするとより精度があがるのかもしれないけど、回答速度がけっこう落ちるので自分の求める性能とトレードオフなのかな。詳しいことは調べてみましょう。
ちなみに Ollama を走らせているマシンをサーバー化して他のマシンからアクセスすることができるみたいなのでそれも試してみたい。tailscale とかで簡単につなげられれば自宅のハイスペマシンを自前の ChatGPT みたいにつかえるんじゃないかな。
VS Code の github.copilot.chat.byok.ollamaEndpoint をいじればよさそう?